


Webinar: Explainable AI for Disease Prediction in Pets
Eine große Managed-Care-Organisation, die Patienten mit chronischen Erkrankungen wie Herzinsuffizienz und Atemwegserkrankungen versorgt, stand vor einer Herausforderung, die in Gesundheitssystemen häufig auftritt: Die wertvollsten klinischen Informationen sind oft in Freitext und unstrukturierten Entlassungsberichten von Krankenhäusern verborgen.
Die manuelle Extraktion dieser Informationen ist langsam, ressourcenintensiv und für Ärzte, die unter Zeitdruck stehen, unrealistisch. Um dieses Problem zu lösen, schloss sich die Organisation mit Spryfox zusammen, um ein robustes, skalierbares System für die zuverlässige Datenextraktion und klinische Qualitätssicherung aufzubauen.
Die Herausforderung
Die Organisation wollte Erkenntnisse auf Patientenebene nutzen, um die klinische Entscheidungsfindung zu verbessern, aber wichtige Informationen wie Medikamentenanpassungen, Anamnese und Diagnosen waren häufig in inkonsistenten, handschriftlichen oder schlecht formatierten Dokumenten enthalten.
Entlassungsberichte variierten stark in ihrer Struktur, enthielten Rechtschreibfehler und präsentierten oft mehrere Medikamente in langen Absätzen oder Tabellen mit inkonsistenter Formatierung.
Obwohl modernste NLP-Tools für das Gesundheitswesen insgesamt gute Leistungen erbrachten, reichte es nicht aus, sich ausschließlich auf automatisierte Extraktion zu verlassen. Die Organisation benötigte:
- Qualitätssicherung auf Patientenebene, nicht nur Genauigkeit auf Entitätsebene
- Einen systematischen Ansatz zur Identifizierung von Fehlern, fehlenden Feldern und unplausiblen Werten
- Eine Feedbackschleife, die es Ärzten ermöglichte, die Systemleistung zu überprüfen, zu korrigieren und kontinuierlich zu verbessern
- Eine Entlastung des klinischen Personals - bei weiterhin menschlicher Überprüfung
Spryfox wurde beauftragt, eine Lösung zu entwickeln und zu implementieren, die diesen Anforderungen gerecht wurde.
Die Lösung
Spryfox entwickelte einen durchgängigen, NLP-gesteuerten Qualitätssicherungs-Workflow, der auf fortschrittlichen, speziell für das Gesundheitswesen entwickelten Sprachmodellen basiert. Das Framework umfasste drei Kernkomponenten:
- Automatisierte Entitätsextraktion
Mithilfe von OCR- und NLP-Pipelines für das Gesundheitswesen extrahierte das System:
- Medikamentennamen
- Dosierung und Einnahmeintervall
- Demografische Daten der Patienten
- Erkrankungen
- Daten und Zeitangaben
Es verarbeitete Freitext, Tabellen und auch fehlerhaft geschriebene Dokumente.
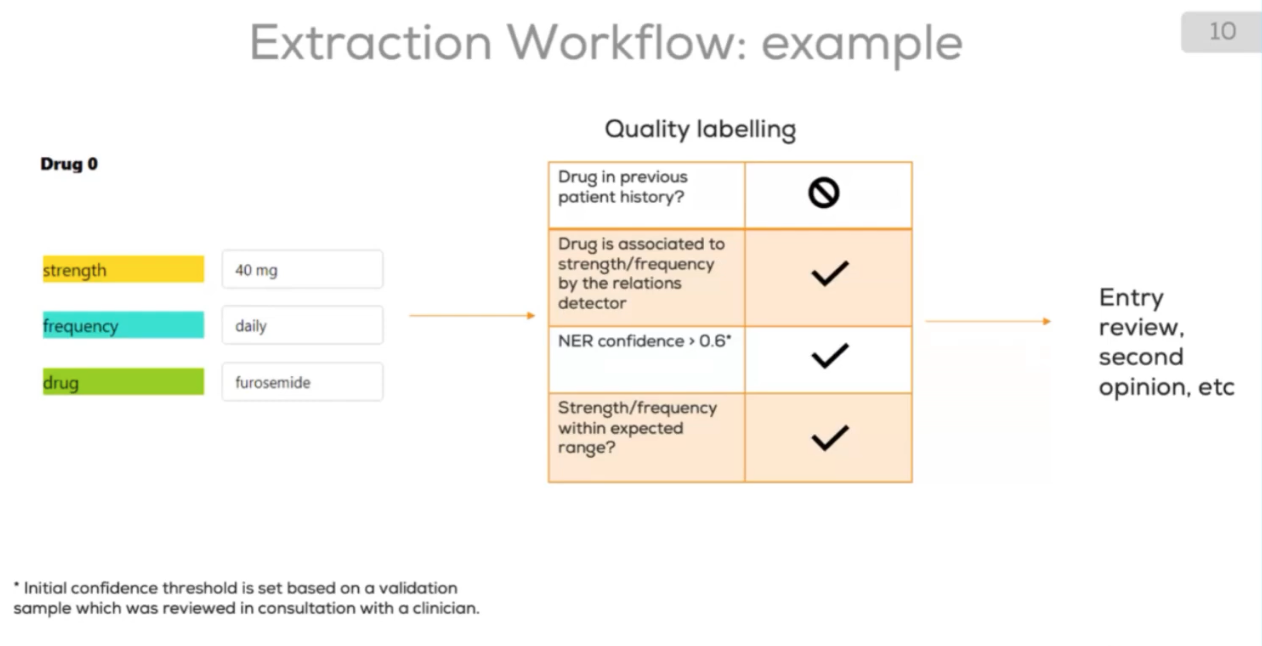
 2. Intelligente Qualitätskennzeichnung
2. Intelligente Qualitätskennzeichnung
- Das Team entwarf vier gezielte Qualitätsregeln für die Extraktion von Medikamenten:
- Konfidenzschwellen für wenig verlässliche Ergebnisse
- Erkennung von Unstimmigkeiten bei Medikamentennamen oder Dosierungen
- Abgleich mit der Krankengeschichte, um neu angesetzte Medikamente zu erkennen
- Erkennung unvollständiger Angaben - etwa fehlende Medikamentennamen, Dosierungen oder Einnahmeintervalle
Jeder extrahierte Eintrag erhielt ein automatisch zugewiesenes Qualitätslabel, das angab, ob eine Überprüfung durch einen Arzt erforderlich war.
- Auf Kliniker abgestimmter Prüfablauf
Das System sorgte für ein Gleichgewicht zwischen Effizienz und Sicherheit:
- Gezielte Überprüfung von Elementen, die gegen Qualitätsregeln verstoßen
- Randomisierte Kontrollüberprüfung von Dokumenten, die alle Prüfungen bestanden haben, um die Erkennung von falsch-negativen Ergebnissen sicherzustellen
Ein integriertes Änderungsprotokoll zeichnete jede Änderung durch einen Kliniker auf und unterstützte so die kontinuierliche Optimierung von Schwellenwerten und Regeln.
Die Auswirkungen
- Das System wurde anhand von 144 Entlassungsbriefen aus Krankenhäusern evaluiert und erkannte erfolgreich mehr als 1.300 Medikamente. Zu den wichtigsten Erkenntnissen gehörten:
- 23% der Medikamente waren im Vergleich zur Krankengeschichte des Patienten neu eingeführt und wurden zur Überprüfung entsprechend gekennzeichnet.
- Bei 44% fehlten Angaben zur Dosierung oder Einnahmeintervallen, was auf die Art und Weise zurückzuführen ist, wie Texte in der Praxis verfasst werden, und unterstreicht den Wert von dokumentenbezogenen Regeln gegenüber einer alleinigen Verwendung von NLP.
- Nur 9% der Medikamente und 5 % der Dosierungen mussten nach ärztlicher Prüfung angepasst werden – das System lieferte also eine hohe Trefferquote, während der QS-Prozess die verbleibenden Fehler zuverlässig auffing.
Das Ergebnis
Durch dieses NLP-gestützte Qualitätssicherungs-Framework profitiert der Managed-Care-Anbieter nun von einem skalierbaren, auf Ärzte abgestimmten System zur Extraktion hochwertiger Daten aus unstrukturierten medizinischen Dokumenten.
Die Lösung verbindet klinisches Fachwissen mit technischer Innovation, reduziert den Arbeitsaufwand, verbessert die Genauigkeit und ermöglicht fundiertere und sicherere Entscheidungen auf Patientenebene.
Daten in Chancen verwandeln
Spryfox arbeitet mit globalen Organisationen aus datenreichen Branchen zusammen, um KI-gesteuerte Lösungen zu entwickeln, die verborgene Werte erschließen. Diese Zusammenarbeit zeigt, wie ein durchdachter Ansatz in Bezug auf Datenqualität, Workflow-Design und Einbeziehung von Klinikern unstrukturierte klinische Daten in umsetzbare Erkenntnisse verwandeln kann.
KI-Strategie, prädiktive Modelle, KI-Produkte – Spryfox hilft Ihnen, die richtigen Chancen zu erkennen und in robuste Lösungen zu übersetzen.
Kontaktieren Sie uns für eine unverbindliche Bewertung, wie KI aus Ihren Daten Wert schöpfen kann.


